Rechercher des images dans le CDN de Geotribu#
Parcourir le CDN via l'interface web#
L'accès en lecture à notre entrepôt d'images accumulées depuis toutes ces années est ouvert  et c'est même un passage recommandé pour tout contributeur/rice :
et c'est même un passage recommandé pour tout contributeur/rice :
- adresse : https://cdn.geotribu.fr
- identifiant :
invité - mot de passe :
geotribu_bemyguest2020
En plus de permettre un petit voyage dans le temps, autant que toutes ces ressources servent en plus de notre site  . Merci de ne pas en abuser en respectant le fair-use. Pensez également à créditer les auteur/es.
. Merci de ne pas en abuser en respectant le fair-use. Pensez également à créditer les auteur/es.
Chercher une image#
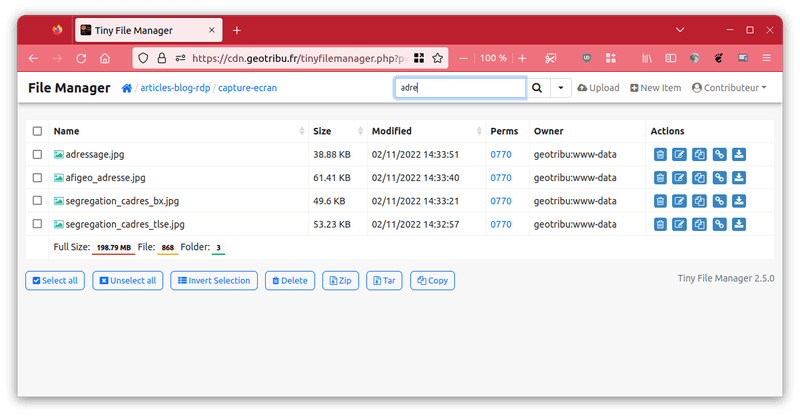
Filtrer le dossier courant#
La barre de recherche en haut permet de filtrer sur le nom du fichier parmi ceux du répertoire courant. A noter qu'il faut attendre que l'ensemble des fichiers du répertoire soient listés pour que ce la fonctionne.
Recherche avancée#
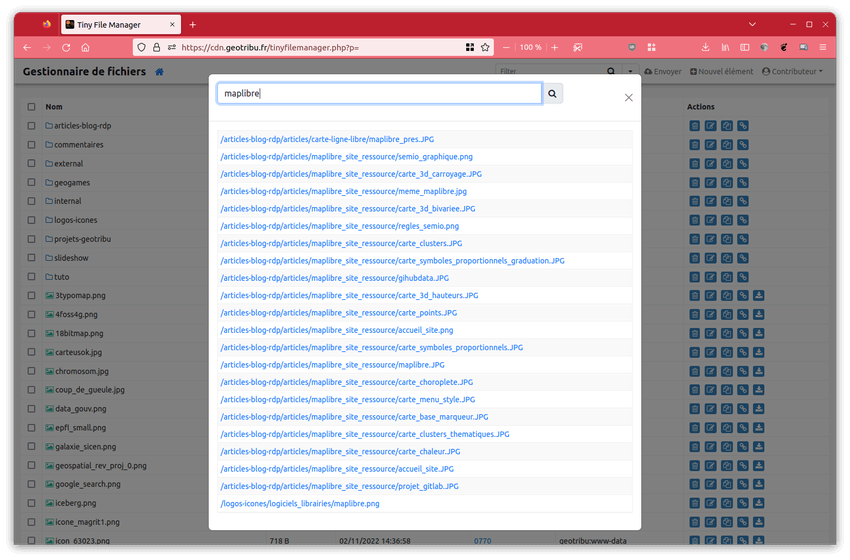
Il est également possible d'effectuer une recherche dans l'arborescence en cliquant sur le menu descendant à droite de la barre de filtre et de sélectionner "Recherche avancée" :
Faire une recherche avec le CLI Geotribu#

Si l'interface graphique vous semble trop longue ou la recherche assez fine ou que vous n'avez pas les identifiants sous la main, il est possible d'interroger l'index des images stockées généré avec [lunr.py] toutes les heures et qui est accessible librement.
En quelques mots :
pip install geotribu
geotribu img search satellite
[...]
geotribu img search --filter logo "name:qgis"
Pour aller plus loin, consulter :
- l'article d'introduction
- la documentation du CLI, en particulier la page des exemples consacrés à la recherche d'images
Commentaires
Ce contenu est sous licence Creative Commons BY-NC-SA 4.0 International 


